大數據存儲組件TiDB原理與實戰 數據處理和存儲支持服務詳解
TiDB作為新一代融合型分布式數據庫,其核心設計目標之一就是高效處理海量數據并提供強大的存儲支持服務。在實戰應用中,理解其數據處理與存儲原理是構建穩定、高性能系統的關鍵。
一、數據處理架構與流程
TiDB的數據處理遵循分層、解耦的設計哲學,主要分為兩層:
- 計算層(TiDB Server):
- 無狀態SQL層:負責接收SQL請求,進行語法解析、語義分析、查詢優化,生成分布式執行計劃。它不直接存儲數據,因此可以輕松水平擴展,應對高并發查詢。
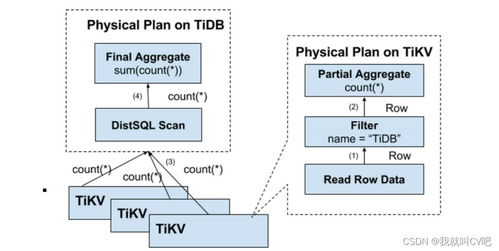
- 分布式執行引擎:將優化后的執行計劃下推到存儲層(TiKV)進行并行計算(“謂詞下推”、“聚合下推”),極大減少了網絡傳輸和數據移動的開銷,提升了復雜查詢(如Join、聚合)的效率。
- 存儲層(TiKV Server & TiFlash):
- TiKV - 行式存儲引擎:作為核心的在線事務處理(OLTP)存儲層,采用分布式鍵值存儲模型。數據以Region(默認約96MB-144MB的連續數據段)為單位,通過Raft協議在多副本間實現強一致性和高可用性。所有數據操作(增刪改)都是基于Raft Log的復制狀態機模型,確保ACID事務特性。
- TiFlash - 列式存儲引擎:作為分析型查詢的加速器,它通過異步復制TiKV中的行數據并轉換為列式存儲。這種設計使得TiDB具備了HTAP(混合事務/分析處理)能力,分析查詢可以直接在TiFlash上執行,利用列存的壓縮率高、掃描快的優勢,且不影響TiKV的OLTP性能。
二、存儲支持服務的關鍵特性與實戰
- 彈性擴縮容:
- 原理:基于Region的調度機制。PD(Placement Driver)組件持續監控集群狀態,當某個TiKV節點的Region數量或負載過高/過低時,PD會自動發起Region的遷移(如分裂、合并、轉移Leader),從而實現數據的動態再平衡。
- 實戰:在業務增長期,只需通過運維工具(如TiUP)添加新的TiKV/TiFlash節點,PD會自動將部分數據遷移到新節點,整個過程對業務透明。縮容時同理,PD會確保待下線節點上的數據安全遷移至其他節點后再完成下線。
- 分布式事務與一致性:
- 原理:采用Google Percolator模型實現分布式樂觀鎖事務。通過一個全局授時中心(PD分配單調遞增的時間戳)來定義事務的先后順序,并利用兩階段提交(2PC)保證跨Region事務的原子性。
- 實戰:開發時無需過多考慮分布式事務的復雜性,像使用單機數據庫一樣編寫事務代碼即可。但需注意,在高沖突場景下(如頻繁更新同一行),樂觀鎖可能導致事務提交失敗率升高,此時可能需要調整業務邏輯或考慮使用悲觀鎖模式(TiDB默認支持)。
- 高可用與容災:
- 原理:數據在TiKV層默認保存3副本,分布在不同的物理節點/機架上,通過Raft協議保證少數副本故障時數據不丟失、服務不間斷。PD本身也是多實例集群,通過ETCD實現選主和元數據高可用。
- 實戰:任何單點或少數節點故障(如磁盤損壞、機器宕機),集群都能自動進行Leader重選和副本補全,實現RPO≈0,RTO<30秒的故障恢復。結合跨數據中心部署方案(如DR Auto-Sync),可構建同城或異地容災體系。
- 實時分析與HTAP:
- 原理:TiFlash作為列存副本,通過Raft Learner角色異步從TiKV同步數據,形成行列混合的存儲格局。優化器會根據查詢代價智能選擇從TiKV(點查、更新)或TiFlash(全表掃描、復雜分析)讀取數據。
- 實戰:對于需要實時報表或即席分析的場景,無需構建復雜的ETL管道到獨立的數據倉庫。只需為相關表通過SQL命令添加TiFlash副本(
ALTER TABLE t SET TIFLASH REPLICA 2),后續的分析查詢即可自動獲得加速,實現“一份數據,兩種處理模式”。
三、實戰優化建議
- 熱點處理:監控PD Dashboard中的熱點Region,對于頻繁訪問的小表,可通過
SPLIT TABLE預分裂Region來分散負載;對于順序寫入熱點(如按時間戳自增主鍵),可考慮使用Shard Row ID或隨機前綴。 - SQL性能調優:充分利用執行計劃分析(
EXPLAIN ANALYZE),關注是否有效下推計算到存儲層。為分析查詢創建合適的TiFlash副本,并為高頻查詢模式建立合適的索引(TiDB支持全局二級索引)。 - 存儲配置:根據數據特性和訪問模式配置合適的Region大小、副本數量和位置策略(通過PD的Label實現機架/可用區感知部署)。
TiDB通過計算與存儲分離、行存與列存共存、數據自動調度等核心設計,為大數據場景下的數據處理與存儲提供了高度彈性、一致且高效的“一站式”支持服務。在實戰中,深入理解其原理并善用其特性,是充分發揮其潛力的不二法門。
如若轉載,請注明出處:http://m.9962333.com/product/48.html
更新時間:2026-02-20 05:50:52